Tabpyとは?TableauにPythonを連携する手順をわかりやすく解説

データビジュアライゼーションの強力なツールであるTableauを、さらに進化させたいと思ったことはありませんか?
Pythonの計算力と組み合わせることで、その可能性は大きく広がります。
この記事では、TableauとPythonを連携させるための鍵となるTabpy(Tableau Python Server)の基本概念から、具体的な導入手順、さらにはTabpyを使ったデータ可視化事例までを詳しく解説していきます。
Tabpyを使えば、複雑なデータ分析を直感的なビジュアルで表現でき、より深いインサイトが得られるようになるでしょう。
TableauとPythonの架け橋であるTabpyを用いてデータを自在に扱い、ビジネスに活かす力を手に入れましょう。
Tabpy(Tableau Python Server)とは?
Tableau公式サイトによると、TabPy (Tableau Python Server)とは、ユーザーがTableauの表計算を介してPythonスクリプトと保存された関数を実行できるようにすることでTableauの機能を拡張する、分析拡張機能の一種です。
すなわち、Tabpyは「TableauとPythonを連携させることで、Tableau上でPythonライブラリを活用し、より高度なデータビジュアライゼーションを実現する」ために利用する機能です。
Tabpyを使うことで、Tableau単体では実現できない高度な統計処理や機械学習モデルの適用が可能になります。
たとえば、「顧客の購入履歴データから次に購入可能性の高い商品を予測する」といった分析が行えるようになるでしょう。
実際にTabpyを利用する際は、Tableauのダッシュボード上でPythonスクリプトを書いて実行する流れになります。このスクリプトはTabpyサーバーに送信され、処理された結果がTableauに戻され、リアルタイムでのデータ更新や予測値の視覚化が可能となります。
このようにTabpyは、Tableauの機能を大きく拡張し、より深いデータのインサイトを得るための強力なツールです。TableauやPythonに慣れている方であれば、簡単に始めることができ、自身の分析スキルを大幅に向上させることができるでしょう。
![]() Tableau初心者でTableauの具体的な学習方法について知りたい方は、以下の記事も参考にしてみてください。
Tableau初心者でTableauの具体的な学習方法について知りたい方は、以下の記事も参考にしてみてください。
◆【初心者向け】Tableauの学習方法ロードマップ オススメの学習コンテンツとともに
Tabpyの利用手順
ここでは、実際にTabpyを利用する流れをご紹介します。
Tabpyを利用するには、以下4ステップの設定を行う必要があります。
Step1:Pythonをインストールする
Step2:Tabpyを起動する
Step3:TableauにTabpyを接続する
Step4:Tableau上でPythonを実行する
また、参考情報として、「Tabpy Client」(定義した関数をTabpyサーバー上に保存するツール)についても簡単に解説します。
【Step1】Pythonをインストールする
まず初めに、Tabpyを利用する上での基本となる「Pythonのインストール」を行います。
主なインストール方法は、以下の3通りあります。
- Anaconda経由でインストールする
- Python公式サイトからインストールする
- Githubからダウンロードする
今回は、Anaconda経由でインストールする方法で進めていきます、
ダウンロードセクションから、お使いのオペレーティングシステム(Windows、Mac等)に合った最新バージョンを選択してください。
インストーラーをダウンロードした後、指示に従ってインストールを進めます。
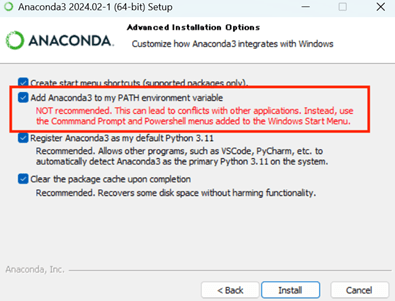
インストール中には、「AddAnacondan to my PATH」のオプションを選択することを忘れないでください。これにより、コマンドラインからPythonを簡単に起動できるようになります。
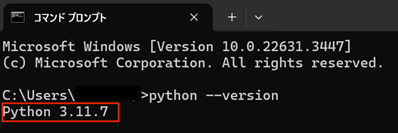
インストールが完了したら、コマンドプロンプト(Macの場合はターミナル)を開き、「python –version」と入力して、インストールが正しく完了したかを確認します。
正しくバージョンが表示されれば、Pythonのインストールは成功です。
【Step2】Tabpyを起動する
Pythonのインストールが完了したら、次はTabpyを起動します。
Tabpyを起動することで、TableauからPythonのスクリプトを実行する橋渡しができるようになります。
コマンドプロンプト(Macの場合はターミナル)を開き、「pip install tabpy」と入力して、Tabpyをインストールしてください。
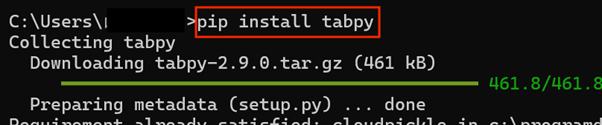
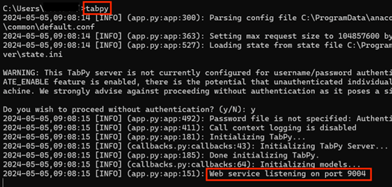
インストール後、ターミナルにtabpyと入力するとTabpyサーバーが起動します。
サーバーが起動すると、コンソールにはポート番号(通常は9004)が表示されます。
これが、TableauとTabpyが通信するためのポートになります。この手順を踏むことで、TableauからPythonスクリプトを呼び出す準備が整います。
【Step3】TableauにTabpyを接続する
Tabpyが起動した後は、Tableauとの接続を設定します。これにより、Tableau内からPythonスクリプトを使用してデータ分析を行えるようになります。
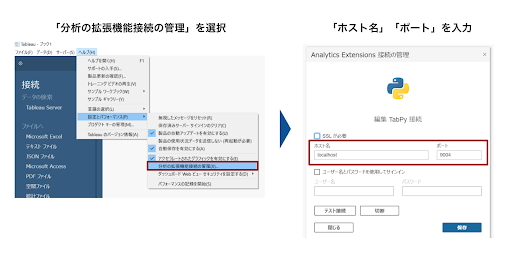
まず、Tableauを開いてメインメニューの画面上部にある「ヘルプ」>「設定とパフォーマンス」>「分析の拡張機能接続の管理」>「Tabpy」を順にクリックします。
「新規Tabpy接続」の画面で、ホスト名を「localhost」、ポート番号を「9004」と入力します。
【Step4】Tableau上でPythonを実行する
TableauとTabpyが接続されたら、次はTableau上でPythonスクリプトを実行してみましょう。これにより、データ分析や高度な計算を行うことができます。
TableauとTabpyの連携の流れは、以下の3ステップで実行されます。
Step1:計算フィールドの入力【Tableau】
Step2:計算フィールドの実行【Tabpy】
Step3:計算フィールド結果の出力【Tableau】
Step4-1:入力
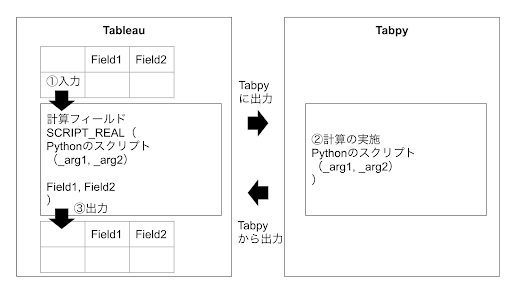
Tableauの「新しい計算フィールドの作成」から、Pythonで実行するスクリプトを記載します。
上図において、_arg1やarg2と記載しているものは、TableauからPythonのスクリプトに渡す引数を示しています。
SCRIPT_REATは、Pythonのスクリプトの戻り値がREAL型(浮動小数点数)であることを宣言するものです。
Step4-2:実行
計算フィールドにスクリプトを記載すると、Tabpyの方にデータが出力され計算が実行されます。
ここの段階で、操作をする必要はありません。
Step4-3:出力
計算が終了すると、Tableauの方で計算結果が出力可能になります。
Tableau上で計算フィールドをビューにドラッグすることで、Pythonスクリプトの実行結果を視覚的に確認できます。
以上の3Stepにより、Tableauのビジュアライズ機能とPythonの強力なデータ処理能力を組み合わせることが可能になり、より深いデータ分析が行えるようになります。
【参考】Tabpy Clientの利用方法について
Tabpy Clientとは、事前に定義した関数をTabpy上に保存(デプロイ)しておくために使われるツールです。
このツールを使うことで、Tableau上で複雑な計算フィールドを作成したり、作成済みのモデルや関数を再利用したりすることができます。
Tabpy Clientを利用するには、Tabpyを起動した状態でJupyter notebook上で関数を定義し、Tabpyにデプロイする必要があります。
Tabpy Clientを利用するには、コマンドプロンプト(Macの場合はターミナル)を開き、「pip install tabpy-client」と入力してインストールを行います。

次に、保存したい関数を記述するためのJupyter notebookを起動します。Anaconda NavigatorからJupyter notebookを起動します。
tabpy_clientをインポートした後にclientを定義します。
![]()
その後、定義したい関数を記述します。この例では引数x、yを足し算するための関数を定義します。
戻り値を記載するreturnのところでは、tolist()を適用することで、リスト型に変換しています。
Tableau側で戻り値を処理する場合には、ndarray型では処理できないためlist型に変換する必要があります。

上記のコマンドを実行したことで、Tabpyには関数がデプロイされています。Jupyter notebook上で関数の確認をすることも可能です。

Tableauの計算フィールドで定義した関数を利用する場合には、上記のようにresultsを確認したのと同じように関数の実行をスクリプトとして記述します。
Tableau計算フィールドでの記述

このようにJupyter notebook上でのモデルや関数のを定義を行うことで、Tableau側での操作を簡略化することが可能となります。
【実践】Tabpyを活用した、Tableauでのデータ可視化事例
ここでは、Titanicの生存データをサンプルに利用して、Tabpyの使い方を示します。大まかな流れとしては、以下の4つになります。
- トレーニング用のデータを用意
- 重要と思われる特徴量を取得し、モデルを作成
- モデルから入力値に対する予測値を返す関数を定義
- Tabpy Serverにデプロイ
Titanicのデータでの目的変数は、生存を示すフラグであるserviveを利用します。説明変数は、客室の等級(pclass)、性別(sex)、年齢(age)、タイタニックに同乗している兄弟/配偶者の数(sibsp)、タイタニックに同乗している親/子供の数(parch)、料金(fare)、客室番号(cabin)を利用してみます。モデルとしては決定木を使って生存のフラグを分析します。
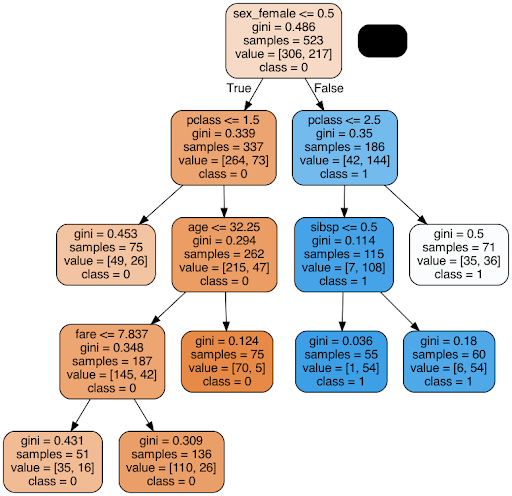
モデル作成までのPythonのスクリプトは下記のようなものを利用しています。

上記のスクリプトを実行すると決定木のグラフを得ることができます。結果から見ると、sex_female、pclass、age、sibspが重要と思われる変数なので、この44つのダミー化された変数を抽出して、再度モデルを作成・フィッティングするという作業を最後に行うことで、モデルを作成しています。
モデルが完成したら次にTabpy Serverにデプロイします。デプロイのためのコード例は下記のような形です。モデルの引数として、ダミー化された引数を渡す想定で、sex、pclass、age、sibspという引数を関数に渡して、モデル内で処理できるようにしています。

関数のデプロイまで完了した後は、Tableauからの操作になります。「Tabpyの利用手順」にてご紹介した手順からTabpy ServerとTableauの接続を行います。
接続後は、計算フィールドから下記のような形で今回デプロイした関数であるclf5dを呼び出します。引数としては、決定木のモデルに対応するものを順番に指定しています。
ここでの計算フィールドの名称として「tabpy_query_clf5」と名付けられたこの計算処理は、生存/非生存の予測を返すものになります。

予測値自体は色々な使い方ができるのですが、例えば、テストデータでみたとき、男女ではやはり女性の方が生存のフラグの予測がより1に近い濃い水色なっていることが分かります。
他にも乗船客の詳細な属性データが利用可能な場合では、属性に対して生存/非生存の予測値がどのように関係しているのかなど生存確率を踏まえた分析が可能となります。
まとめ
この記事を通じて、Tabpyとその設定手順、さらに具体的な活用事例について詳しく解説しました。
TabpyはTableauとPythonの強力な連携を実現するツールであり、高度なデータ分析や機械学習モデルをビジュアライゼーションの世界に取り入れることができます。
具体的には、Pythonをインストールし、Tabpyを設定してTableauに接続することから始めます。
このプロセスを経て、Tableau上でPythonスクリプトを直接実行できるようになります。
Tabpyの導入により、TableauユーザーはPythonの強力なデータ処理機能を活用することが可能となり、データビジュアライゼーションの可能性をさらに広げることができます。
これにより、企業や研究者は複雑なデータセットからより豊かなインサイトを引き出せるようになるでしょう。
この記事が、TableauとPythonを連携させたデータ分析を検討している方々にとって、理解を深めるための役立つガイドとなれば幸いです。
<Tableau>
弊社ではSalesforceをはじめとするさまざまな無料オンラインセミナーを実施しています!
>>セミナー一覧はこちら
また、弊社ではTableauの導入支援のサポートも行っています。こちらもぜひお気軽にお問い合わせください。
>>Tableauについての詳細はこちら