Power BIでテキストマイニングする方法を解説



テキストデータはお客様のアンケート集計や市場のトレンド、競合情報など定性的な情報が多く、データを効率的に活用し分析することは簡単ではないですよね。そこで登場したのがBIツールを活用したテキストマイニングです。
Power BIはグラフやマトリクスなど数値データを分析するツールであることはよく知られています。しかし、テキストデータの分析ができることを知らない方、多いのではないでしょうか。テキスト分析を目的にPower BIを導入する方はほとんどいらっしゃらないかもしれません。
実はPower BIのテキスト分析機能は優秀で、簡単にビジュアル化まで実現することができます。
Power BIでできるテキストマイニング
今回はPower BIでテキストマイニングをトライしてみます。
手順は“テキストデータ分析”⇒“ビジュアル化”で解説します。
テキストデータ分析
↓テキストデータ分析はPower Queryから実行します。Power BIを起動し、Power Queryを実行してください。データはテキストであれば何でも構いません。
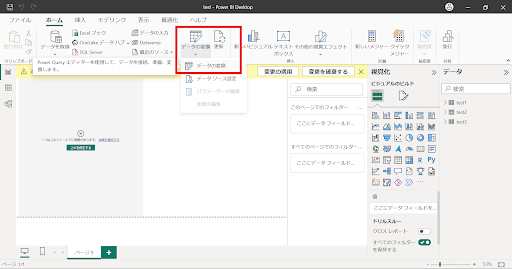
↓Power Queryエディターの“Text Analytics”を選択します。
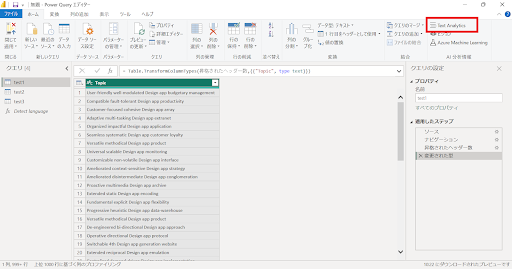
↓Text Analyticsを選択すると以下の画面が表示されます。
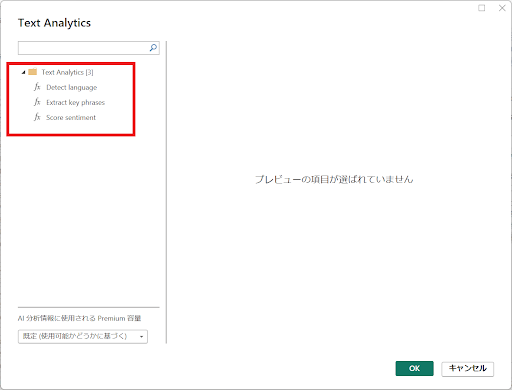
Text Analyticsは以下の機能があります。
Extract key phrases:テキストからキーとなるフレーズを抽出します。
Score sentiment:センチメント分析をします。
それではそれぞれの機能を試してみましょう。
Detect language
Detect languageとはテキストデータの自動言語検出機能です。
これは、テキストデータ内の文やフレーズがどの言語で書かれているかを自動的に判定が可能です。Power BIの自然言語処理(NLP)機能の一部として提供されており、多言語のテキストデータを効果的に処理し、適切な分析や可視化を行うために利用されます。
Detect languageのメリットは以下の通りです。
多言語データの処理: テキストデータが複数の言語で書かれている場合、それぞれの言語に合わせた分析や処理を行いたいことがあります。Detect language機能を使用することで、テキストデータを自動的に言語ごとに分類し、適切な処理を行うことができます。
可視化と分析: Power BI内で言語の検出を行うことで、異なる言語のテキストデータを効果的に可視化し、適切な分析を行うことができます。言語ごとに違った傾向や特徴を把握するための出発点として利用されます。
自動カテゴリ分類: 言語の検出を活用して、テキストデータを異なるカテゴリやトピックに自動的に分類することも可能です。これにより、大量のテキストデータを効率的に整理し、分析の基盤を築くことができます。言語の検出は、Power BIの自然言語処理機能をより効果的に活用し、多様な言語で書かれたテキストデータを分析する際に非常に役立つ機能です。
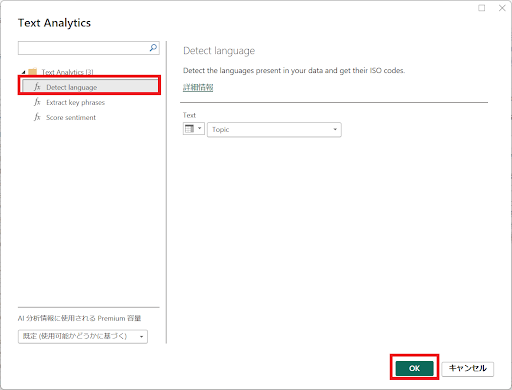
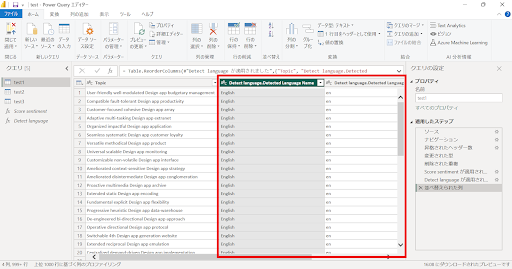
↓Detect languageを選択し、“OK”をクリックします。列名はサンプルデータの列名“Topic”を選択しています。
↓分析が完了すると、Power Queryエディターに選択した列の言語が、新たに追加された列に表示されます。サンプルのデータは英語でしたので、“English”となっています。
Extract key phrases
Extract key phrasesはテキストからキーとなるフレーズを抽出します。
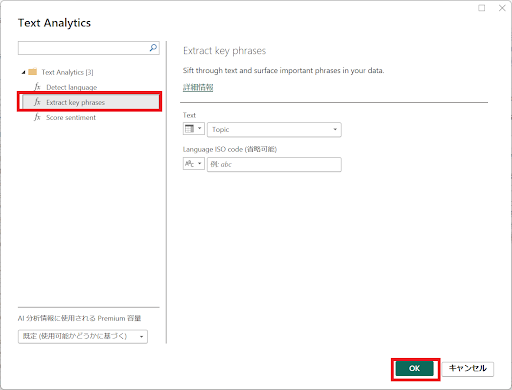
↓Extract key phrasesを選択し、OKをクリックします。列名はサンプルデータの列名“Topic”を選択しています。
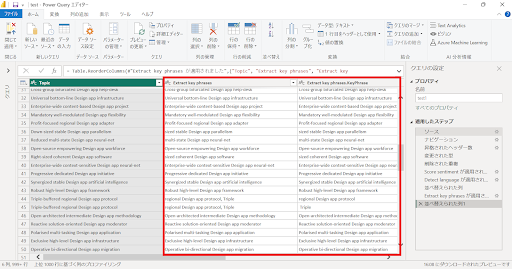
↓テキスト文からフレーズを抽出できています。テキスト文を分解しフレーズごとにデータが作成できていることが確認できます。
Score sentiment
Score sentimentはセンチメント分析をします。
センチメント分析はテキストデータ内の感情や意見の極性(ポジティブ、ネガティブ、またはニュートラル)を示す数値です。このスコアは、テキスト内の単語やフレーズの選択、文脈、文法などを分析して算出されます。センチメントスコアが高い場合、テキストの感情的なトーンはポジティブであり、逆にスコアが低い場合はネガティブな感情を表しています。中立的なテキストは、センチメントスコアが中間の範囲に位置することが一般的です。
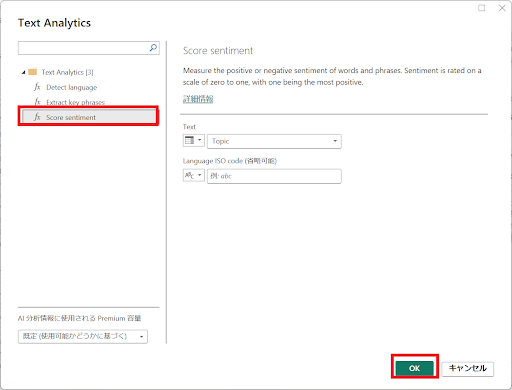
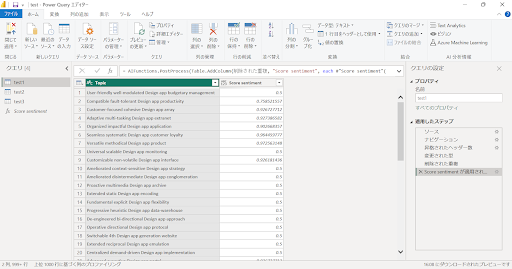
↓Score sentimentを選択し、OKをクリックします。
↓分析した列に対して、センチメントスコアの列が表示されています。
テキストデータ分析は以上です。次にビジュアル化をしていきましょう。
ビジュアル化
テキストデータ分析で抽出した各データをビジュアル化していきましょう。
グラフ・マトリクス
ビジュアル化の方法は数値データと同じビジュアルを使用します。数値データではないのでカウントなどを使用し、分析できるような定量的なデータに変える必要もあります。
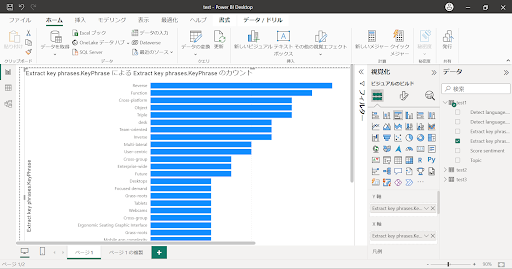
↓グラフ:抽出されたワードの出現数が多い順に表示させています。
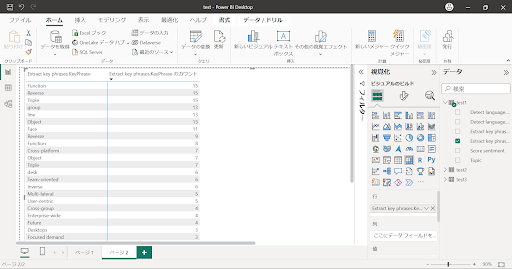
↓マトリクス:抽出されたワードの出現数が多い順に表示させています。
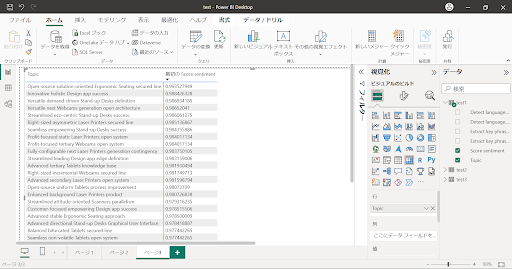
↓マトリクス:センチメントスコアが高い順位に表示させています。
前処理がいらないワードクラウドビジュアル
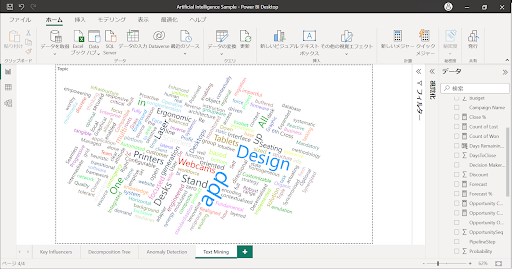
Power BIのテキストデータを分析するビジュアルとしては“ワードクラウド”が代表的です。
ワードクラウドのビジュアルは前述のテキストデータ分析などの前処理を必要とせず、簡単にワードクラウドを実現することができます。
↓当社でもPower BIでワードクラウドを表現する方法としてビジュアル“ワードクラウド”を使用した例を紹介させていただいています。ご参考ください。
https://frogwell.co.jp/blogs/pbi-textmining/
テキストマイニングの注意点
Power BIを使用したテキストマイニングにおいて、いくつかの注意点があります。Power BIに限らずですが、以下にいくつかのポイントを挙げてみましょう。
データ前処理の重要性: Power BI内でテキストデータを分析する前に、データの前処理を適切に行うことが重要です。テキストデータをクリーニングし、不要な文字や記号を取り除くことで、正確な分析結果を得ることができます。今回はPower Queryで使用したAI Analyticsの各機能を利用したのみでしたが、取得したデータによっては事前に処理する必要があります。
テキスト解析の正確さ: Power BIは自然言語解析機能を提供していますが、解析結果の正確さは常に保証されているわけではありません。感情分析やトピック分析の結果には、エラーや誤解釈が含まれる可能性があるため、検証が必要です。
データ量によるパフォーマンスへの影響: テキストデータが大量にある場合、Power BIのパフォーマンスに影響を与える可能性があります。十分なメモリや処理能力を持つ環境で作業するか、データのサンプリングや集約を検討してパフォーマンスを最適化することが大切です。
プライバシーとセキュリティ: テキストデータはしばしばプライバシーやセキュリティの問題を引き起こす可能性があります。個人情報や機密情報を含むデータを処理する際には、適切なセキュリティ対策を講じることが必要です。
Power BIを活用したテキストマイニングは非常に強力な分析手法ですが、正確性と解釈のバランスを保つために、慎重なアプローチと注意が必要です。
まとめ
-
- Power BI のテキストマイニングを“テキストデータ分析”、“ビジュアル化”でトライ
-
- テキストデータ分析はPower QueryのAI Analyticsから以下の機能を使用できる
Detect language:言語を抽出
Extract key phrases:テキストからキーとなるフレーズを抽出
Score sentiment:センチメント分析
-
- ビジュアル化はテキストデータ分析で抽出したデータをグラフやマトリクスで実行
Power BIのワードクラウドのビジュアルであれば前処理は不要
-
- テキストマイニングの注意点
必要に応じて前処理、分析結果の検証、プライバシーやセキュリティ問題への注意が必要

<Power BIハンズオンセミナー>
弊社ではPower BIをはじめとするさまざまな無料オンラインセミナーを実施しています!
>>セミナー一覧はこちら
<Power BIの導入支援>
弊社ではPower BIの導入支援を行っています。ぜひお気軽にお問い合わせください。
>>Power BIの導入支援の詳細はこちら
<PowerBIの入門書を発売中!>
弊社ではPower BIの導入から基本的な使い方・活用方法の基礎などをわかりやすく解説した書籍も販売しています。
>>目次も公開中!書籍の詳細はこちら
