Tableauでのデータ分析サイクル



目次
この記事では、ビジネスの現場で統計分析を使うサイクルとともに、手法の基礎、Tableauでの基本操作を解説していきます。
統計分析のサイクル
データ分析の手法をビジネスの現場で取り入れるにあたり、参考にできるモデルがあります。それが、CRISP-DM(CRoss-Industry Standard Process for Data Mining)というものです。この概念自体は、データマイニングの時代から提唱されている分析プロセスですが、その内容は、現在でも汎用的に適用できるものです。
分析担当者がCRISPサイクルを実現するためには、ビジネス領域の担当者、エンジニアやデータサイエンティストとも協力しながら進めることが求められます。具体的にそれぞれのプロセスで実施するべきことについて説明をします。
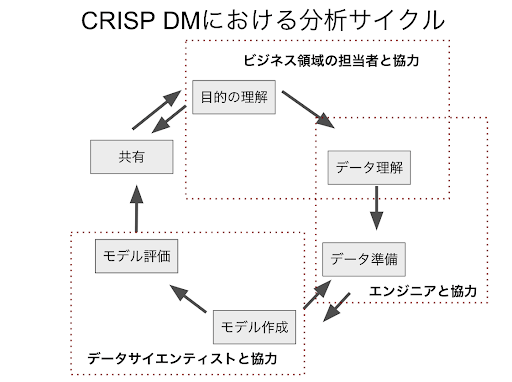
目的の理解
ビジネス目的の理解とは、分析におけるゴールを設定することと同じです。ビジネスのフェーズや視点によっても、評価するべき視点は変わります。例えば、新規のプロダクトであれば、新規ユーザの獲得が考えられます。プロダクト運用という視点では、コンバージョンポイント直前での離脱なども考えられます。
ビジネスのスキームなどを踏まえて最終的に評価するべき指標を設定することがこの段階では求められます。
データの理解
データの理解とは、データの意味や生成ルールを理解すると同時に、どのようなビジネス要求や背景で、作られたものなのかを理解することです。
データの意味のチェックとしては、外れ値、欠損値、行に対して1つの値が割り振られる列か(DBでいうところの主キーかどうかということ)ということをチェックします。
生成ルールの理解という意味では、アプリやサイトのどのボタンを押したり、操作した場合に生成されるカラムなのかというソフトウェアの仕様を理解しておくことも重要です。
データの理解では、集計表やヒストグラムなど基本的な記述統計の手法を利用します。記述統計によるデータの解釈だけでもビジネスの現場では大きな発見となる場合もありますので、データ分析プロセスでも最も重要なプロセスになります。
データの準備
データの準備は、マスタテーブルの結合、集約、表記揺れの修正、外れ値の処置、NULLの置換など多岐に渡ります。分析を進める上で重要な作業になります。
(前処理の方法)
モデルの作成・評価
モデル作成、モデル評価のプロセスは、Pythonで行われます。データを集計、可視化することで示唆が得られることも多くあります。分析の目的によっては、機械学習モデルを用いた予測、分類やその他統計的な手法を用いる場合もあります。目的に応じて、分析手法を選ぶプロセスです。
共有
最後のプロセスである共有では、作成した集計表やモデルの結果を分かりやすい形で共有を進めます。Tableauのダッシュボードを利用してTableau ServerやTableau Onlineを利用してデータからの知見を共有することが有効です。
分析手法の基礎
ここでは、Tableauで公開されているサンプルデータを利用して、データ理解や分析のための基本的な方法について紹介をします。サンプルデータはこちらから利用できます。
今回は、Titanic Passenger Listというデータを例に操作方法などを紹介します。
このデータはTitanic号の乗客リストです。このデータでは、surviveというカラムで、1が立つと生存、0だと非生存となるフラグになっています。
以下では、実際にデータを使って「データを理解する」というプロセスをTableauでどのように行うかを紹介します。
アウトカムに対応する集計表を作成する
今回のデータでは乗客の生存/非生存と関係したであろう要因を検討することにします。まずデータ理解をするに当たって、生存/非生存に分けたときに、どのような特徴があるのかを整理します。
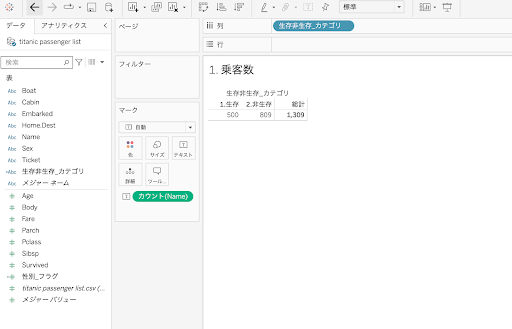
まずは分析対象となる乗客の全体数を把握しておきます。どの分析のシーンにおいても「分析対象となる集団とその数は何か」は必ず把握しておくことが重要です。今回は、アウトカムである生存/非生存のフラグをメジャーネームとして取り扱えるように計算フィールドを追加しました。
この分析の集団は、1,309人です。
背景表をみる
次にアウトカムに関係のありそうなメジャーバリューが、アウトカムとどのように関係していそうかを把握します。生存/非生存のそれぞれの集団における特徴を大まかに掴むための作業です。
タイタニックの乗客リストには、乗客の特徴を示す項目がありますが、「乗客の属性」「乗客の選択行動によって生まれたであろう特徴」の観点で下記の6つをピックアップして、生存/非生存とどのように関係があるのかを調べます。なお、性別は男性を1、女性を0としたフラグに置き換えています。
sex: 性別(male=男性、female=女性)
sibsp: タイタニック号に同乗している兄弟や配偶者の数
parch: タイタニック号に同乗している親や子どもの数
fare: 旅客運賃
pclass: 旅客クラス(1=1等、2=2等、3=3等)。裕福さの目安。
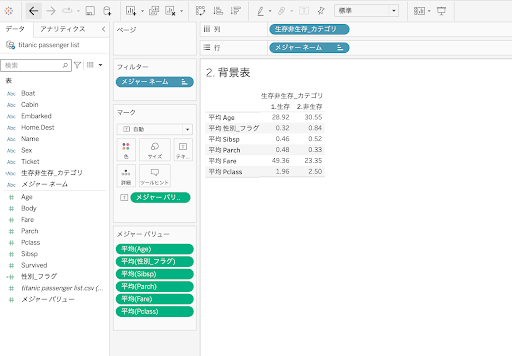
この集計表では、メジャーバリューの平均値を取っています。最大値、最小値、中央値など各種統計量を追加してみることも必要ですが、実際の分布はヒストグラムでみることとし、この集計表では平均値を利用しています。
このデータの特徴として、生存者は、年齢が若くかつ男性が少ないことが分かります。同乗している親や子供の数も多少多い傾向にあります。加えて、生存の方が、運賃が高く、旅客クラスも1等に近いことが分かります。
カテゴリや属性ごとに詳しくみる
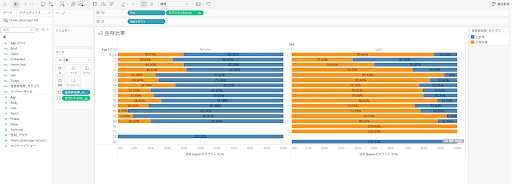
上記の集計表から年齢や性別という観点で、生存/非生存の割合が異なりそうに見えました。Tableauで、年齢を5歳区分にして、5歳区分別性別でみた生存/非生存の割合を見てみます。
年齢のような連続値をカテゴリ化するには、カテゴリ化したいメジャーバリューで「作成」>「ビン」を選択して設定します。また今回は生存/非生存の割合を出したいので、計算表で「合計に対する割合」を「ペイン(横)」に設定しました。
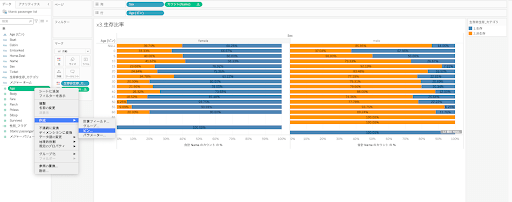
データをみてみると、女性の方が圧倒的に生存率が高いことが分かります。加えて男性でも10歳までの子どもは生存率が相対的に他の年齢よりも高くなっています。データからも女性、高齢者、若年層という属性が避難の際の判断に使われていたことが考えられます。
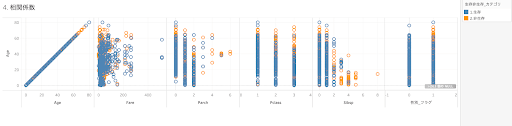
メジャー(連続値)同士の相関関係をみる
データをみる際には、値同士の相関関係をみることも重要になります。特に生存の分布が多いところはどこかという点も加味しながら、組み合わせを探していきます。
メジャーバリュー同士の相関係数をみる際には、組み合わせでみたい項目を行、列それぞれに同じ並びで追加をします。その際、ツールバーにある分析>メジャーの集計のチェックを外します。
今回は年齢との関係をみていきます。兄弟や配偶者の数が多いほど、年齢層は若年者が多く、かつ非生存の関係にあることが分かります。また客室の等級が下がるほど、年齢が高い乗客の非生存が目立つようになっています。

このように基本的な集計や分布をみることで、データの基本的な傾向を理解することができます。このプロセスを行うことでモデルを作成した際にも、基本的な傾向からみて不自然さがないかなどチェックすることができるようになります。
まとめ
データの理解として、分析対象集団の数の把握、背景表の作成、相関関係の分析という手法を紹介しました。この手法はどのような分析テーマであっても汎用的に利用できるものです。
モデルの作成の前に行う基本的な記述統計の方法です。Tableauを使うことで、数値から見える傾向を踏まえてデータを「インサイト」に変えるためにも不可欠な手順をいち早く実行することができるようになります。
<Tableau>
弊社ではSalesforceをはじめとするさまざまな無料オンラインセミナーを実施しています!
>>セミナー一覧はこちら
また、弊社ではTableauの導入支援のサポートも行っています。こちらもぜひお気軽にお問い合わせください。
>>Tableauについての詳細はこちら