Power BIのセマンティックモデルとは 概要や使い方、設計方法を分かりやすく解説



目次
- 1. セマンティックモデルとは?
- 1.1 意味と背景(“意味的に整理されたデータモデル”)
- 1.2 Power BIにおけるセマンティックモデルの位置づけ
- 1.3 旧称「データセット」との関係
- 2. セマンティックモデルの構造を理解する
- 2.1 データソース/テーブル/メジャーの関係
- 2.2 リレーションとコンテキストの概念
- 2.3 Power BI Service上での構成(Fabric連携を含む)
- 3. セマンティックモデルの作成・共有手順
- 3.1 Power BI Desktopでモデルを構築する
- 3.2 Power BI Serviceへ発行(=セマンティックモデル化)
- 3.3 別レポートから再利用する手順
- 4. セマンティックモデルを使うメリット
- 4.1 モデルの再利用による開発効率向上
- 4.2 データ定義の一貫性確保
- 4.3 セキュリティ・アクセス権の集中管理
- 5. 設計時のベストプラクティス
- 5.1 モデル名・テーブル名の命名規則を統一する
- 5.2 カラム・メジャーの命名とコメント設定
- 5.3 データ更新スケジュールと依存関係の管理
- 6. セマンティックモデルと他機能との違い
- 6.1 データフローとの違い
- 6.2 データセット共有との違い
- 6.3 Fabricとの連携ポイント
- 7. まとめ:Power BIの“共通言語”としてのセマンティックモデル
Power BIでレポートが増えてくると、「レポートごとに売上定義が違う」「部署ごとに似たレポートが乱立する」「どの数字が正なのか分からない」といった問題が起きやすくなります。
こうした混乱を防ぐ土台となるのが「セマンティックモデル(Semantic Model)」です。セマンティック(semantic)は「意味的な」という意味で、セマンティックモデルは「業務上の意味を整理したデータモデル」と捉えるとイメージしやすいです。
この記事では、Power BIにおけるセマンティックモデルの概要、構造、作成・共有手順、メリット、設計のポイントをコンパクトに整理します。複数レポートを一元管理したい担当者向けに、専門用語もできるだけかみ砕いて解説します。
セマンティックモデルとは?

意味と背景(“意味的に整理されたデータモデル”)
セマンティックモデルは、単にデータを格納するだけでなく、ビジネス上の意味やルールをまとめて定義したモデルです。個々のレポートが好き勝手に計算式や関係を持つのではなく、「このモデルの定義に合わせる」ことで全体の整合性を保ちます。
たとえば、次のような情報をひとまとめに管理します。
- テーブル同士の関係(どのテーブルがどの軸でつながるか)
- 売上や利益などのメジャー定義
- フィルターやロール(役割)による見せ方の違い
「数字の定義書」と「データ構造」をセットで持っているイメージだと理解しやすいです。
Power BIにおけるセマンティックモデルの位置づけ
Power BIでは、レポートやダッシュボードの一段下にセマンティックモデルが存在します。レポートはこのモデルに接続し、そこで定義されたテーブルやメジャーを使って可視化を行います。
構造を簡単に整理すると、次の三層構造です。

レポートは「UI」、セマンティックモデルは「頭脳」、データソースは「素材」と考えるとイメージしやすいです。
旧称「データセット」との関係
Power BI Serviceでは、以前は「データセット(Dataset)」という名称で表示されていました。現在は同じ概念が「セマンティックモデル」として扱われています。
名称が変わったことで、「単なるデータの塊」ではなく「意味とルールを持つモデル」であることが意識しやすくなりました。過去の資料や画面で「データセット」と書かれている場合も、基本的には同じ層を指すと考えて問題ありません。
セマンティックモデルの構造を理解する

データソース/テーブル/メジャーの関係
セマンティックモデルは、次のような要素の組み合わせで成り立っています。
- データソース:SQL Database、Data Warehouse、ファイルなど、元データの置き場所
- テーブル:ファクトテーブル(売上明細など)、ディメンションテーブル(顧客・商品・店舗など)
- カラム:キー、属性、数値項目など、テーブルの列
- メジャー:売上合計、利益率など、集計ロジックを定義した指標
これらを「業務でそのまま使える形」に整理し直したものがセマンティックモデルです。レポート作成者は、テーブルやメジャーを選ぶだけでビジネスの数字を扱えるようになります。
リレーションとコンテキストの概念
テーブル間のリレーション(関係)は、集計結果やフィルターの効き方を決める重要な要素です。どのテーブル同士をどのキーで結ぶか、どちら向きのフィルターを許可するかによって、スライサー操作時の“コンテキスト”が変わります。
よくある構成は次のようなものです。
- 日付テーブル→売上テーブル
- 顧客テーブル → 売上テーブル
- 店舗テーブル → 売上テーブル
「日付スライサーを動かすと売上明細がどう絞られるか」といった挙動は、すべてリレーション設計に依存します。セマンティックモデルの段階で正しく設計しておくことで、レポート側では余計な調整をせずに済みます。
Power BI Service上での構成(Fabric連携を含む)
Power BI Service や Microsoft Fabric 環境では、セマンティックモデルはワークスペース内の1つのリソースとして管理されます。1つのワークスペースに共通モデルを置き、複数レポートやExcelから参照する構成が一般的です。
Fabric を利用している場合は、OneLake 上の Lakehouse/Warehouse とセマンティックモデルを組み合わせて、下記のような三層構造で設計します。
- 下層:OneLake+Lakehouse/Warehouse(ストレージ・計算基盤)
- 中層:セマンティックモデル(意味とロジックの層)
- 上層:レポートやExcel、外部ツール(可視化・利用の層)
このように層を分けることで、データ基盤とBIを一体として運用しやすくなります。
セマンティックモデルの作成・共有手順
Power BI Desktopでモデルを構築する
セマンティックモデルは、まず Power BI Desktop 上で作成します。基本的な流れは次のとおりです。
- データソースに接続する
- Power Query で不要な列の削除や型変換などの整形を行う
- モデルビューでテーブルのリレーションを定義する
- DAXでメジャー(売上合計、利益率など)を定義する
※上記は通常のPowerBI desktopの作業手順と変わりません。
この段階で「どのテーブルが軸か」「どのメジャーを共通指標にするか」を整理しておくと、後からの運用がぐっと楽になります。
Power BI Serviceへ発行(=セマンティックモデル化)
Desktopで作成したレポートを Power BI Service に発行すると、ワークスペース内に
- レポート
- セマンティックモデル

の2つが作成されます。Service側では、セマンティックモデル単体を選択して更新スケジュールや行レベルセキュリティ(RLS)、権限設定などを行います。
「レポートを発行すると同時に、セマンティックモデルもクラウド上に配置される」と認識しておくと分かりやすいです。
別レポートから再利用する手順
既存のセマンティックモデルは、別レポートから再利用できます。
手順は以下の通りです。
- Power BI Desktop から「Power BI のセマンティックモデル」を選ぶ。
- 対象のセマンティックモデルを指定すると、そのモデルをベースに新しいレポートを作成できます。
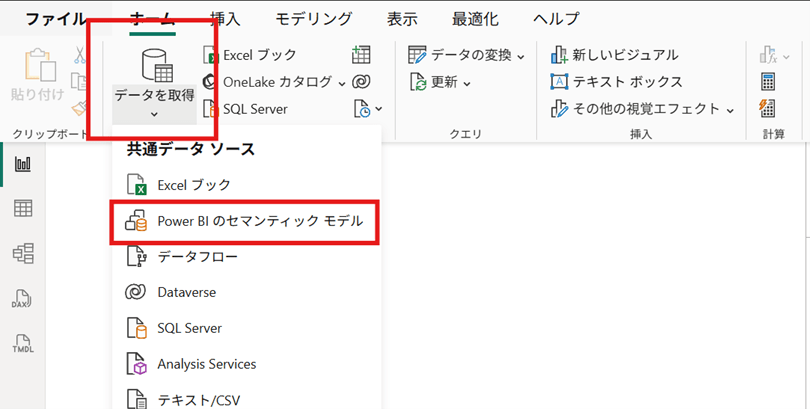
構成イメージを簡単な表にすると次のようになります。

共通モデルを軸に、目的別のレポートをいくつも増やしていく、という考え方です。
セマンティックモデルを使うメリット

モデルの再利用による開発効率向上
1つのセマンティックモデルを複数レポートで共有できるため、毎回同じモデルを作り直す必要がなくなります。新しいレポートを作る際も「既存モデルに接続してグラフを作る」だけで済むため、初期設計の手間を大きく減らせます。
また、共通メジャーを修正すれば、それを参照しているすべてのレポートに自動的に反映されます。修正漏れを防ぎやすくなる点も、再利用の大きなメリットです。
データ定義の一貫性確保
売上、利益、利益率、会員数などの指標定義がレポートごとに異なると、「どの数字が正しいのか」という議論が増えてしまいます。セマンティックモデル側でメジャー定義を一元管理することで、全レポートで同じ定義を使い回せるようになります。
数字合わせではなく、中身の議論に集中しやすくなる点が大きな価値です。
セキュリティ・アクセス権の集中管理
行レベルセキュリティ(RLS)などのアクセス制御も、セマンティックモデル側で設定できます。店舗ごと・エリアごとの閲覧範囲をモデル側で定義しておけば、レポートはそのルールを自動的に継承します。
権限設定をレポート単位で重複管理しなくてよくなるため、統制と運用の両面で負荷を下げることができます。
設計時のベストプラクティス

モデル名・テーブル名の命名規則を統一する
セマンティックモデルは長期運用が前提なので、命名を整えるだけでも後々の混乱を防げます。モデル名は「目的+対象」(例:売上分析セマンティックモデル_国内)のようにし、テーブル名も業務用語に寄せておくと、利用者が意味を把握しやすくなります。
カラム・メジャーの命名とコメント設定
カラム名やメジャー名も、利用者目線で分かりやすくすることが大切です。「~合計」「~率」など接尾辞を揃え、日本語/業務用語で統一し、重要なメジャーには簡単な説明コメントを付けておくと、現場での迷いを減らせます。
データ更新スケジュールと依存関係の管理
セマンティックモデルは複数レポートに影響するため、どのデータソースやデータフローに依存しているか、いつリフレッシュが走るかを整理しておくことが重要です。上流のデータフローやDWHの一覧と、各モデルのリフレッシュ時間帯だけでも簡単にまとめておくと、障害時の原因特定がしやすくなります。
セマンティックモデルと他機能との違い

データフローとの違い
Power BI の「データフロー」と「セマンティックモデル」は混同されがちですが、
実際には、データ処理のどの段階を担当するかが大きく異なります。

全体の流れ
外部データ
↓
データフロー(前処理・整形)
↓
セマンティックモデル(意味づけ・統一ロジック)
↓
レポート/ダッシュボード
このように、「データフローで共通の整形ロジックを作り、その結果をセマンティックモデルが参照する」という分担で設計するのが一般的です。
データセット共有との違い
従来の Power BI では「データセット共有」が一般的な運用でしたが、
現在は Fabric の登場もあり、これらは “セマンティックモデル”として整理される方向 に統合されています。
本質的な違いは名称よりも 運用思想 にあります。
セマンティックモデル運用で重要なポイント
- レポートごとにDAXやロジックをばらばらに書かない
- KPI・指標定義を“モデル側”に寄せて統一する
- すべてのレポートが同じモデル=同じ定義を参照する状態を作る
つまり、「どこにロジックを置くか」という問題であり、セマンティックモデルを中心に据えることで 分析の整合性・再利用性・保守性が飛躍的に向上します。
Fabricとの連携ポイント
Microsoft Fabric を導入している場合、セマンティックモデルは OneLake 上のデータ基盤と密接に統合される存在 になります。
Fabricと組み合わせるメリット

連携設計の基本スタンス
- 下層のデータ基盤(Fabric)にデータ管理・更新処理を集約
- 上層(セマンティックモデル)で指標定義・ロジック・アクセス制御を統一
- すべてのレポートはセマンティックモデルを参照する構造にする
このことで、「データ基盤 × BI」の一体運用 が可能になり、組織全体でのデータ活用レベルが大きく向上します。
まとめ:Power BIの“共通言語”としてのセマンティックモデル

セマンティックモデルは、Power BIにおける「共通の意味を持つデータモデル」です。1つのモデルを複数レポートで共有することで、定義の一貫性を保ちながら、開発と運用の効率を高められます。
- モデルを再利用して開発工数を削減できる
- 指標定義を一元管理し、数字の“ブレ”を防げる
- セキュリティや権限もモデル側で集中管理できる
といったメリットは、レポート数や利用者が増えるほど大きくなります。
Power BIやFabricを本格的に活用していくうえで、セマンティックモデルは欠かせない基盤です。

<Power BIハンズオンセミナー>
弊社ではPower BIをはじめとするさまざまな無料オンラインセミナーを実施しています!
>>セミナー一覧はこちら
<Power BIの導入支援>
弊社ではPower BIの導入支援を行っています。ぜひお気軽にお問い合わせください。
>>Power BIの導入支援の詳細はこちら
<PowerBIの入門書を発売中!>
弊社ではPower BIの導入から基本的な使い方・活用方法の基礎などをわかりやすく解説した書籍も販売しています。
>>目次も公開中!書籍の詳細はこちら
