オープンデータは機械学習のデータセットに最適?医療業界での活用方法も紹介



目次
- 1. オープンデータ・データセットとは?
- 2. 機械学習にはデータセットが必要
- 2.1 機械学習に用いる3種類のデータセット
- 3. オープンデータと機械学習を組み合わせる3つのメリット
- 3.1 開発コストを削減できる
- 3.2 精度の高いコンテンツを開発できる
- 3.3 短期間で開発できる
- 4. 機械学習に利用できるオープンデータ27選
- 4.1 機械学習に便利なオープンデータの代表例・身近な例
- 4.2 オープンデータと自作データセットを組み合わせる
- 5. オープンデータを機械学習に用いる際の注意点4つ
- 5.1 1. 自社の目的や課題、用途に合ったデータを選ぶ
- 5.2 2. データの著作権に留意する
- 5.3 3. 必要ないデータを排除してから検証する
- 5.4 4. 定期的にデータの更新や改善を行う
- 6. オープンデータを用いた機械学習の活用例
- 6.1 NDBを用いた患者の疾患予測
- 6.2 病床機能報告データを用いた入院先病院の紹介
- 7. まとめ
人工知能の一種である機械学習は、膨大なデータセットから反復学習を行い、ルールやパターンを発見する技術です。 機械学習を用いると、未知のデータに対する予測や分類が可能になります。
機械学習を用いて、新たな価値を創出しようとお考えの企業や団体の担当者の方は、オープンデータを活用してみてはいかがでしょうか。誰でもダウンロードし、利用できるオープンデータがあれば、機械学習のデータセットを、より簡単に準備できます。
この記事では、機械学習に便利なオープンデータ・データセットについて解説します。入手方法やおすすめのサイト、活用時の注意点などを、わかりやすく体系的にお伝えするので参考にしてください。
オープンデータ・データセットとは?

オープンデータとは、機械で判読できる形式を持ち、二次利用が認められているデータのことです。オープンデータは一般向けに公開されており、商用利用の場合を含め、誰でも自由にダウンロードや複製、加工などが行えます。
またデータセットとは、一定の目的や対象のために集められたデータの集合体です。データセットは、機械学習を行うための膨大なサンプルデータの役割を果たします。
以上より、「オープンデータ・データセット」とは、二次利用ができるルールで公開されたデータの集合体のことです。縮めて「オープンデータセット」と呼ばれる場合もあります。
機械学習にはデータセットが必要
機械学習では、コンピュータが膨大な情報(データセット)を自動で処理し、情報に隠されたルールやパターンを見つけ出します。そのため、機械学習を行ううえで、データセットは必要不可欠な要素です。
なお、データセットに含まれる個別のデータは、すべて一定の形式に整えられています。それゆえ、コンピュータはすべてのデータを同様に処理することができ、機械学習が円滑に進みます。データが適切に整理されているという意味でも、データセットは機械学習に欠かせません。
機械学習に用いる3種類のデータセット
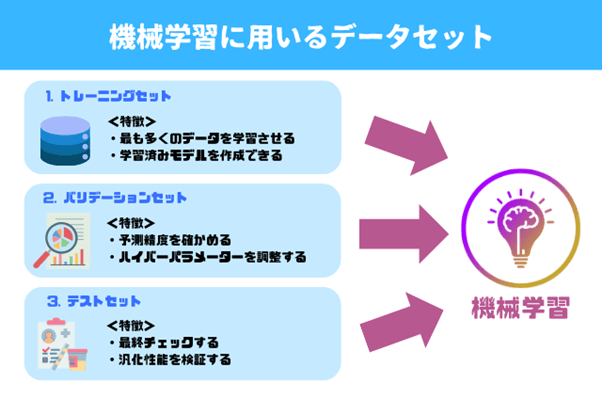
図1:機械学習に用いるデータセット
機械学習に用いるデータセットは、主に「トレーニングセット」「バリデーションセット」「テストセット」の3種類に分類されます(図1)。
以下では3種類それぞれの概要を紹介するので、参考にしてください。
1. トレーニングセット
トレーニングセットとは、コンピュータに学習をさせるために用いるデータセットのこと。機械学習における最初の工程で利用され、データの規模も一番大きいです。
コンピュータをトレーニングセットで学ばせると「学習済みモデル」を作ることができます。これから紹介する2種類のデータセットは、その学習済みモデルの精度調整や最終チェックのために用いられます。
2. バリデーションセット
バリデーションセットは、学習済みモデルの精度を調整するために用いるデータセットです。学習済みモデルにバリデーションセットを試して予測結果を出し、その予測がどれだけ当たっているかを確認します。
また予測結果をもとに、機械学習のアルゴリズムを統御する「ハイバーパラメーター」を調整します。バリデーションセットを活用した以上の作業により、予測精度の高い学習済みモデルを作ることが可能です。
3. テストセット
テストセットは、バリデーションセットを通した予測精度の高い学習済みモデルを、最終チェックするためのデータセットのこと。テストセットは、これまでに機械が学習したことのないデータで構成されており、機械の予測性能がどれだけ汎用なものかを確かめられます。
テストセットを用いた検証で、十分な結果が得られれば、そのモデルは完成となります。
オープンデータと機械学習を組み合わせる3つのメリット
機械学習のデータセットにオープンデータは最適です。本来はトレードオフの関係にある生産管理におけるQ(Quality:品質)C(Cost:コスト)D(Delivery:納期)の全てを強化することが可能になります。
オープンデータと機械学習を組み合わせるメリットを見ていきましょう。
開発コストを削減できる
オープンデータは、無料で公開されているため、データセットを入手するコストがかかりません。本来の機械学習の開発プロセスでは、データセットの準備に多くのコストを要します。精度の高い予測には、良質で大量なデータが不可欠です。
本来は、人員コストを投入して、以下のような工程を行う必要があります。
- 必要なデータを特定する
- データを収集する
- データの偏りがないか判断する
- 機械学習しやすい形に加工する
しかし、既に一定の形式にまとめられた大量のオープンデータがあると、これらにかかるコストを大幅にカットすることが可能です。
精度の高いコンテンツを開発できる
国や地方自治体からも、オープンデータは公開されています。国民の膨大なデータが集約されているので、機械学習のサンプル数として申し分ありません。
データ数だけでなく、データのバリエーションも豊富なので、精度の高いコンテンツの開発が期待できます。同じようなデータセットを大量に学習したとしても、機械学習の精度は上がりません。過学習と呼ばれる状態になり、データセットとの適合が良すぎて、汎用性が失われてしまいます。
公的な機関が公開しているオープンデータは、対象とする母数が多いことから、国民のあらゆる属性を網羅しており、過学習の心配がいりません。
短期間で開発できる
オープンデータを用いると、データセットの収集にかかる工程を大幅にカットできるため、短期間で開発できます。余った時間は、コンテンツの品質向上に投下することで、より品質の高いコンテンツが製作できるでしょう。
機械学習に利用できるオープンデータ27選
機械学習に用いるデータセットの入手方法は、オープンセットを活用するか、自作するかのどちらかです。自作するには一定の時間と労力が必要なので、まずは手軽に実践できるオープンデータの活用から始めてみると良いでしょう。
機械学習に便利なオープンデータの代表例・身近な例
昨今はさまざまな機関から多種多様なオープンデータが公表されており、これから機械学習を始める方には良い状況だといえます。以下では、機械学習に活用できる代表的なオープンデータを紹介するので参考にしてください。
総合的なオープンデータ・データカタログ
まずは政府や研究機関などが公開している総合的なオープンデータを紹介します。
e-stat
日本政府による統計データを公開している公的なサイト。開発者が使えるよう、一番高いランクのオープンデータを提供。
DATA GO JP
デジタル庁が手がけるオープンデータに関する情報サイト。各省庁が提供しているオープンデータを検索できる。
国立情報学研究所データリポジトリ
民間企業のデータや音声コーパス、研究者のデータなど、さまざまなデータを提供。国立のデータセット共同利用研究開発センターによる。
Data.gov(US)
アメリカ政府のオープンデータが公開されているサイト。農業や気候、エネルギーをはじめ、さまざまなトピックのデータセットを入手できる。
Harvard Dataverse
ハーバード大学の研究データを公開するリポジトリ。15万以上のデータセットを検索できる。
画像系のオープンデータ
続いて、画像に関するデータセットを公開しているサイトを紹介します。海外サイトが中心で、無料で公開されているものも多いです。
MNIST
機械学習の入門者に利用されることが多い手書き数字のオープンデータベース。60,000のトレーニングセットと10,000のテストセットを公開。
ImageNet
1400万枚以上のカラー写真を無料でダウンロードできる。語彙のデータベース「WordNet」に基づき、単語でデータを検索できるため、利便性が高い。
Deep Fashion
ファッション画像のデータセットを公開。50カテゴリー・80万以上の画像を入手できる。
Google Open Image V4
Googleが公開する900万枚の画像データセット。画像データに対し、ラベルとバウンディングボックスが注釈されている。
CIFAR-10 / CIFAR – 100
8,000万枚のカラー画像がダウンロードできる。画像はラベル付き、サイズは32×32。
動画系のオープンデータ
動画系のオープンデータ・データセットは、以下のような海外サイトで提供されています。画像データ同様、無料で利用できるものも多いです。
YouTube-8M Dataset
YouTubeで1,000回以上再生された動画を800万本集めたデータセット。研究で活用できるレベルのタグ付けがされている。
UCF101-Action Recognition Data Set
セントラルフロリダ大学がYouTubeから収集した、101個のアクションカテゴリを持つ動画のデータセット。アクションカテゴリは25のグループ、グループは4〜7のビデオに細分化。
Moments in Time Dataset
人や動物、物体、自然現象などを含む3秒間のビデオを100万件収録したデータセット。MITとIBMが共同で提供する。
20BN-JESTER DATASET V1
PCの内蔵カメラやWebカメラで撮影した、ハンドジェスチャーの動画を15万以上収集。それぞれの動画には27個のハンドジェスチャーのラベルを付与。
Atomic Visual Actions (AVA)
人の動作(歩行、ジャンプなど)に関する動画のデータセット。Googleが80種類のラベルを付けて提供する。
音声系のオープンデータ
音声系のオープンデータは、以下のようなサイトから入手することができます。海外サイトのみならず、日本のサイトもあり、日本語音声のデータセットも得られます。
The NES Music Database
397タイトル・5,278曲を収録したデータセット。自動で音楽を作成するシステムを作るのに用いられる。
AudioSet
Googleが提供する大規模な音声データベース。人間の声や動物の鳴き声、楽器の音などがダウンロードできる。
声優統計コーパス
3人の声優の音読データをダウンロードできる。日本声優統計学会が提供。
JVSコーパス(日本語多用途音声)
声優や俳優など、100人以上の声(読み上げ音声・ささやき声・裏声)を収録したオープンデータセット。東京大学情報理工学系研究科の高道慎之介助教らが作成。
音声資源コンソーシアム
音声情報処理の研究開発に利用できる、さまざまな音声データベースを公開。
テキスト系のオープンデータ
テキスト・文章系のオープンデータは、以下のようなサイトから入手するのがおすすめです。いずれも日本のサイトであり、日本語文章のデータセットを入手できます。
自然言語処理のためのリソース
自然言語処理に活用できるデータセットやツールの情報を収集、公開。京都大学 大学院情報学研究科 黒橋・褚・村脇研究所のホームページ内。
青空文庫
著作権切れ作品や著者が許諾した作品のテキストデータを公開。青空文庫の作品を形態素解析し、CSVデータを公開している「青空文庫形態素解析データ集」も有名。
SNOW T15:やさしい日本語コーパス
5万文を平易な日本語に書き換えた対訳のデータベース。書き換えは、長岡技術科学大学 自然言語処理研究室の学生5名が人手で実施。
日本語対訳データ
日英翻訳のものを中心に、日本語の対訳文からなるコーパスをリストアップ。統計的機械翻訳システムの学習に利用できる。
Twitter日本語評判分析データセット
2015〜2016年ごろに投稿された534,962件のツイートを分析し、分析結果のデータを公開。
医療系のオープンデータ
医療機関に関連するオープンデータは、以下から入手することができます。医療機器メーカーや販売会社などに利用されています。
NDBオープンデータ
厚生労働省が、各年のレセプト情報や特定健診情報を集計し、オープンデータとして公表。
病床機能報告データ
病床機能報告制度に基づいて、各病院が都道府県に報告した病床機能を集計し、厚生労働省及び都道府県がオープンデータとして公表。
FROGWELL
医療機関や病床、DPCなどのオープンデータを利用しやすいように整え、無料もしくは安価で提供する。
オープンデータと自作データセットを組み合わせる
独自にデータを集め、データセットを自作するという選択肢もあります。競合優位性のある機械学習モデルを作りやすいことが、データセットを自作するメリットです。マクロにはオープンデータを使いつつ、ミクロには自作したデータセットを用い、独自性を持たせるのも良いでしょう。
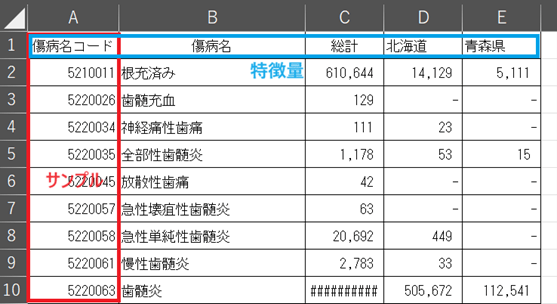
図2:自作データセットの整理方法
データセットの自作には、Excelを活用します。サンプルを縦、特徴量を横とし、データをわかりやすく整理しましょう。サンプルおよび特徴量には、すべて異なる名称を付けてください。なお、Excelに搭載されているセルの結合機能は、データの読み込み時にエラーの原因となるので利用すべきではありません。
またファイル形式はxlsxファイルではなく、csvファイルを選択するのがおすすめです。csvファイルは情報に無駄がないので視認性が高く、機械によるデータ解析も円滑に行えます。
オープンデータを機械学習に用いる際の注意点4つ

オープンデータを活用して機械学習を行う際には、データの選び方や使い方にいくつか注意をしなければなりません。具体的には、以下で紹介する4つのポイントに留意してください。
1. 自社の目的や課題、用途に合ったデータを選ぶ
オープンデータを探す前に、まずは自社の目的や課題、作成する機械学習モデルの用途をはっきりさせましょう。なぜ機械学習を導入するのかをはっきりさせておくことで、的確なデータセットを選ぶことができ、思った通りのモデルができやすくなります。
目的や課題、用途がぼんやりしていると、機械学習を導入しても十分な効果が得られない恐れもあるので注意してください。なお、精度の高いモデルを構築するには、特異的ではなく平均的なオープンデータ・データセットを選ぶことも大切です。
2. データの著作権に留意する
オープンデータには、著作権の対象となる著作物が含まれる場合があります。著作権のあるデータについては、クリエイティブ・コモンズ・ライセンスの表示をすることで、自由に利用できる場合が多いです。しかし、一部には例外的なケースも存在します。
利用規約を確認する、法務担当や外部の専門家に相談するなど、データの著作権に対して適切な対応ができるよう心がけましょう。
3. 必要ないデータを排除してから検証する
オープンデータは、ダウンロードしてそのまま使うのではなく、人為的な分別をしてから活用しましょう。データセットにイレギュラーなデータが含まれていると、学習済みモデルの予測精度が悪くなる恐れがあります。
よって、必要のないデータは排除してから活用するのがおすすめです。
4. 定期的にデータの更新や改善を行う
オープンデータ・データセットは、一度作成したら永久に使い続けられるものではありません。データが古くなったら、十分な意味をなさなかったり、予測精度の低下につながったりする場合もあります。
そのため、作成したら終わりではなく、定期的にデータの更新や検証・改善をする機会を設けるのがおすすめです。
オープンデータを用いた機械学習の活用例
近年、急速な発展を遂げている人工知能(AI)技術。その一種である機械学習をビジネスに用いることで、新たな価値を創出し、利益向上に繋がるかもしれません。オープンデータは、無料で入手できる有用なデータセットなので、導入障壁も比較的低いです。
ここでは、実際にオープンデータを機械学習に用いる活用例を紹介します。
NDBを用いた患者の疾患予測
NDBとは、厚生労働省がホームページで公開している「レセプト情報・特定健診等情報データベース」のことです。全国の患者の診療情報や特定健診データが集約されています。
NDBをデータセットとして機械学習を行うことで、患者の年齢・性別・病歴といった情報から、今後かかりうる疾患を予測することが可能です。病院側は、患者に対して今後気を付けた方がよい疾患を伝えることで、患者からの信頼を獲得できます。
健康診断事業を行っている企業では、診断結果と併せて予測される疾患を提示することで、健康診断に付加価値を与えられ、顧客獲得・維持に繋がるでしょう。
病床機能報告データを用いた入院先病院の紹介
医療機関が都道府県に報告を行っている病床機能報告データには、病院が担っている医療機能の現状や今後に関する情報が集約されています。
地方厚生局が公開する、病院の詳細な診療科が掲載された医療機関一覧表と、厚生労働省が公開する病床機能報告データを組み合わせて、機械学習のデータセットにすることで、患者が入院するのに最適な病院を紹介できます。
具体的な機械学習の流れは、以下のとおりです。
- 病床機能報告データと医療機関一覧表を病院名称で紐づける
- 病床機能報告データと医療機関一覧表を機械学習する
- ユーザーの所在地や傷病に対応する診療科などから、最適な病院を予測する
病床機能報告データには、病床機能ごとに空いている病床数も掲載されています。ユーザーが入力した情報から、傷病に対応する病床機能が存在し、尚且つ病床の空きも十分にある近隣の病院を提案できます。
また、NDBには診療行為ごとに算定回数が多かった二次医療圏が集約されているため、NDBもデータセットに組み込むことで、さらに精度の高い予測が可能になるでしょう。
まとめ
機械学習に必要なデータセットを集めるには、政府や企業、その他団体が公開しているオープンデータを活用するのがおすすめです。オープンデータを使うことで、より手軽に機械学習を始められます。
オープンデータには、無料もしくは安価で利用できるものも多いので、これを機会にぜひ探してみましょう。
<医療系オープンデータ>
弊社では、医療系オープンデータとして
・医療機関マスタ(医科、歯科、薬局)
・DPCデータ
・病床機能報告データ
をご用意しております。
【医療機関マスタ】
厚労省のオープンデータ「コード内容別医療機関一覧表」をもとに作成した医療機関マスタをご提供しています。ご興味のお持ちの方は、お気軽に下記フォームよりお問合せ下さい。
>>無料版の詳細はこちら!
無料版は医療機関(病院・クリニック等)、医薬・医療機器のメーカー・販売会社の方限定です。
>>有料版の詳細はこちら
有料版は、二次医療圏や経営体情報、緯度経度など詳細情報を付与したデータです。カスタマイズも可能です。
【DPCデータ提供サービス】
>>詳しくはこちら
【病床機能報告データ提供サービス】
>>詳しくはこちら
<無料オンラインセミナー開催中!>
弊社ではSalesforceやBIツール、MA、オープンデータなどの活用方法に関する無料オンラインセミナーを実施しています!
>>セミナー一覧はこちら
